
Normalization in Hindi
Normalization
Normalization एक ऐसी प्रक्रिया है जिसमे जटिल और दोहराव (Redundancy) डेटा structure से साधारण (Normal) डेटा structure में परिवर्तित किया जाता है। अर्थात Normalization में टेबल के अनावश्यक और अवन्छिक डेटा को अलग-अलग भाग में बाट कर डेटा को सरल तरीके से प्रदर्शित करता है
दुसरे शब्दों में, Normalization डेटाबेस को व्यवस्थित और सही तरीके से डिजाइन करने की एक प्रक्रिया है। इस प्रक्रिया में, डेटाबेस टेबल्स को इस तरह से Reorganize करते हैं कि डेटा में अनावश्यक दोहराव (Redundancy) और असंगति (Inconsistency) को कम किया जा सके।
सोचिए, यदि एक ही जानकारी बार-बार अलग-अलग जगहों पर दोहराई जा रही है, तो डेटाबेस बड़ा हो जाएगा, उसमें बदलाव करना मुश्किल होगा, और गलतियों की संभावना बढ़ जाएगी। Normalization इसी समस्या को हल करता है।
Example:
Unnormalized Data
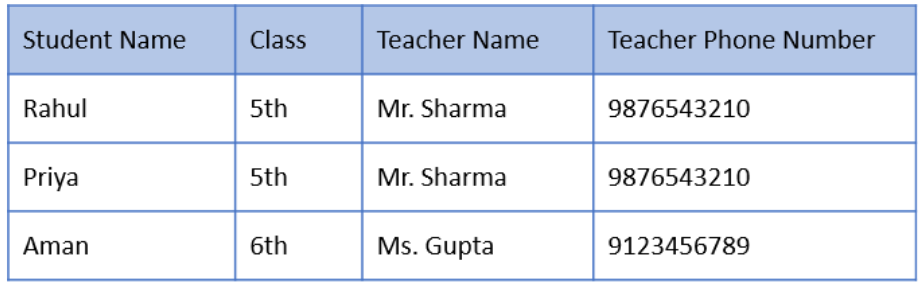
Normalized Data
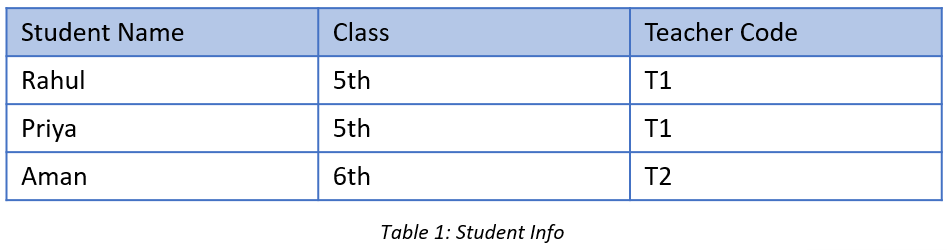
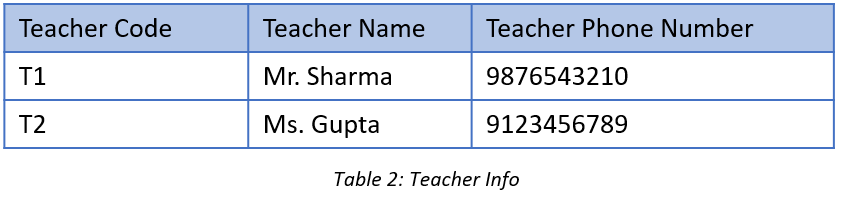
डेटाबेस normalization डेटा को रिडंडेंसी कम करने और डेटा इंटीग्रिटी सुनिश्चित करने के लिए design किया गया है। यह कई नॉर्मल फॉर्म्स (1NF, 2NF, 3NF, BCNF, 4NF, 5NF) में विभाजित है, जो टेबल्स को छोटे, Related Tables में विभाजित किया जाता है। उदाहरण के लिए, एक छात्र-कोर्स टेबल को 1NF में प्रत्येक कोर्स के लिए अलग पंक्ति में विभाजित किया जा सकता है।
यह डेटाबेस टेबल्स को छोटे और अधिक Manageable units में तोड़कर किया जाता है, जिससे डेटा की अखंडता (Data Integrity) और डेटाबेस का प्रदर्शन बेहतर होता है। इस प्रक्रिया में, हम डेटा के बीच के relations को ध्यान में रखते हुए टेबल्स को अलग-अलग भागों में बाँटते हैं। इससे डेटा में बदलाव करना आसान हो जाता है और डेटा की सटीकता बनी रहती है।
Normalization, जिसे 1970 के दशक में e.f .codd ने develop किया था। यह एक व्यवस्थित तरीका है जिससे डेटा को संरचित और दोहराव से मुक्त टेबल्स में बदला जाता है। ।
Advantages
- डेटा को अलग-अलग टेबल्स में बटता है जिससे डुप्लीकेट डेटा कम होता है।
- डेटा की सटीकता और विश्वसनीयता को बढ़ती है।
- इसमें छोटी और विशिष्ट टेबल्स होने से डेटा को अपडेट करना आसान होता है।
- छोटी टेबल्स पर Queries तेज़ी से चलती हैं।
- इसमें डेटाबेस को बड़े स्तर पर मैनेज करना आसान होता है।
Disadvantages
- Normalization के बाद टेबल्स की संख्या बढ़ जाती है, जिससे डेटाबेस डिज़ाइन जटिल हो सकता है।
- डेटा को एक्सेस करने के लिए अक्सर JOINs का उपयोग करना पड़ता है, जिससे Queries धीमी हो सकती हैं।
- अत्यधिक Normalization से डेटाबेस Performance प्रभावित होती है।
- कई टेबल्स बनाने से स्टोरेज स्पेस बढ़ता है, लेकिन वर्तमान में स्टोरेज सस्ता हो गया है।
- कुछ एप्लीकेशन्स (जैसे एनालिटिक्स) को Denormalized डेटा की ज़रूरत होती है, जो normalizetion के बाद मुश्किल हो सकता है।
Types of Normalization
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF)
First Normal Form (1NF)
First Normal Form 1NF में डेटाबेस की टेबल में प्रत्येक column में केवल एक ही value (डेटा) होना चाहिए। इसका मतलब यह है कि किसी भी column में एक से ज्यादा डेटा नहीं होने चाहिए। साथ ही, टेबल में कोई भी पंक्ति (row) दोहराई हुई नहीं होनी चाहिए, यानी प्रत्येक पंक्ति अलग (unique) होनी चाहिए।
इसे उदहारण से समझते है:
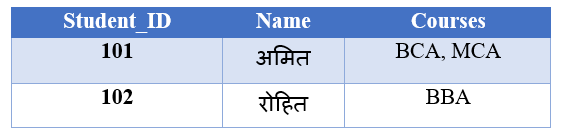
“Courses” कॉलम में एक से अधिक वैल्यू हैं, जो 1NF नहीं है।
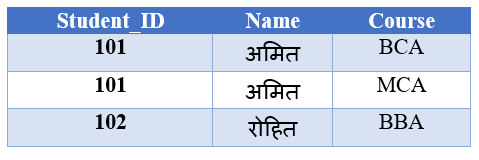
यह 1NF है क्योकि प्रत्येक column में केवल एक ही value (डेटा) है।
Second Normal Form (2NF)
Second Normal Form (2NF) में टेबल पहले से ही 1NF (First Normal Form) में होनी चाहिए, और इसके अलावा टेबल में कोई भी आंशिक निर्भरता (Partial Dependency) नहीं होनी चाहिए। इसका मतलब यह है कि टेबल के सभी non-key attributes पूरी तरह से (primary key पर निर्भर होने चाहिए।
आसान शब्दों में टेबल पहले से 1NF में होनी चाहिए (प्रत्येक column में एक ही डेटा हो)। टेबल में primary key जो है, उस पर प्रत्येक column पूरी तरह से निर्भर हो।
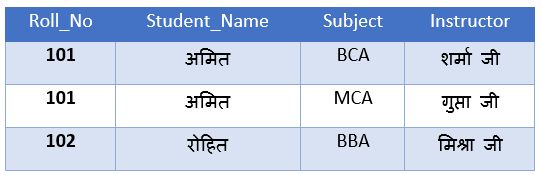
समस्या:
- यहाँ Primary Key = (Roll_No, Subject) है, क्योंकि हर छात्र के पास एक से अधिक विषय (Subjects) हो सकते हैं।
- Instructor कॉलम Subject पर निर्भर है, न कि पूरी Primary Key (Roll_No, Subject) पर।
- यही Partial Dependency है, जिसे हटाना जरूरी है।
After 2NF (टेबल को विभाजित करके Dependency हटाई गई)
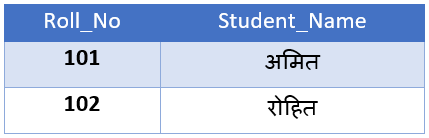
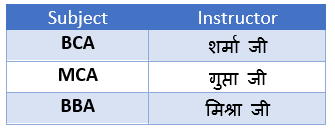
यह टेबल 2NF में है क्योंकि Instructor कॉलम अब Primary Key के किसी भी हिस्से पर निर्भर नहीं है, बल्कि पूरी तरह से Subject पर निर्भर है।